Next: 27.1.2 Program operation Up: 27.1 Codaq Previous: 27.1 Codaq Contents Index
------------------------------------------------------------------- start in s times and Vp/Vs ratio (optionally) 2.0 absolute start time (sec) 0 window length (sec) 20 spreading parameter 1.0 constant v in q = q0*f**v 1.0 minimum signal to noise ratio 2 Noise window in front of signal and length of RMS noise window 15,5 minimum correlation coefficient 0.50 maximum counts to use 64000 number of frequencies and number of octaves (optional) 3 frequencies and bands (optional if octave given) 4,2 8,4 16,8 default stations(1. line) and components (2. line), 30a5 HYA ASK SUE S Z S Z S N -------------------------------------------------------------------
Start in s-times and Vp/Vs ratio (optinal): Normally the coda window starts at twice the S-travel time from the origin, this factor can be varied and might be chosen differently in special cases. Note that the S-time is calculated from the P-time so a P-time must be present. This also means that if a Pn is used, the coda window will start at 2 times the Sn travel time, which might be substantially different from 2 times the Sg travel time. e S-time is calcualted from the P-time using and Vp/Vs = 1.78. Optionally, the user can select an Vp/Vs ratio to be used. This parmeter is optional so parameter files prior to version 8.3 can be used.
Absolute start time: If 0.0, above parameter is used. However if different from zero, an absolute start time relative to the origin time is used for the start of the coda window. This might be useful since different start times (meaning different lapse times) might produce different q-values. To use this parameter, one must be certain to choose it long enough which can be checked with the plots. If the absolute start time is smaller than (Start in s-times) multiplied by the s travel time, the station will be skipped and a message given.
Window length: This is the coda window length in secs. Use at least 20 secs to get stable results.
Spreading parameter: The geometrical spreading parameter used in q-fit, normally 1.0 is used.
Constant
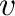 in
in
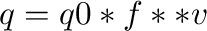 : For all
: For all
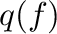 values,
values,
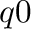 is calculated using a fixed
, use e.g.
is calculated using a fixed
, use e.g.
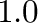 . This parameter has no influence on the individual
. This parameter has no influence on the individual
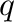 calculations.
calculations.
Minimum signal to noise ratio: In order to accept a q value for the average, the signal to noise ratio must be above this value. The signal to noise ratio is calculated using the last tRMS ( see next parameters) secs of the filtered coda window and the first tRMS secs of the data file window. If the data file starts with noise or in the P signal, the s/n ratio will be in error. A reasonable value is 5.0.
Maximum counts to use: If the count value in a coda window is above this value, the window is not used. The intention is to avoid using clipped values. From SEISAN version 7.2, there is also an automatic checking for clipped values in addition to `maximum counts'.
Noise window in front of signal and length of noise window, tnoise and tRMS: The first number is the number of seconds of noise to plot in front of the signal. In previous versions, 15 secs was hardwired, but sometimes there was not 15 secs of noise before the P. The second number is the length of the noise window used for calculation of the signal to noise ratio. This was earlier hardwired to 5 secs.
Minimum correlation coefficient: In order to use the q value in the average, the correlation coefficient of the coda q fit must be larger than or equal to this value. NOTE. Correlation values are in reality negative, but are always referred to as positive in the following. An acceptable value depends on the data, try to use a value higher than 0.5 (in reality -0.5)
Number of frequencies and number of octaves: Number of frequencies to use, maximum 10, 5 is a good number. The number of octaves for the filter can also be given, then all filters have the same bandwidth.
Frequencies and bands: The corresponding center frequencies and frequency
bands. The frequency band should increase with increasing frequency
to avoid ringing. E.g. 8,4 means that the signal is filtered between
6 and 10 Hz. It is advisable to use constant relative bandwidth
filtering, to get an equal amount of energy into each band. The relative
bandwidth is defined as
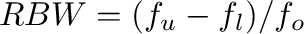 where
where
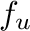 and
and
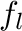 are
upper and lower frequency limit respectively. Such a filter would
be e.g.
are
upper and lower frequency limit respectively. Such a filter would
be e.g.
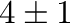 ,
,
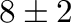 .
.
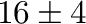 . The frequency representing the energy in a
particular filter band, is the geometric center frequency calculated
as
. The frequency representing the energy in a
particular filter band, is the geometric center frequency calculated
as
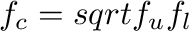 .
Since the user probably wants to calculate coda Q at the given frequency, the normal
option (new in SEISAN7.2) is that
and
are calculated such that the
given bandwidth (e.g. 4 Hz) is used, but the actual
and
will
give the specified central frequency. It is still possible to calculate
as before, where
and
will be exactly as specified (but the
geometrical center frequency will not correspond to specified center
frequency) by giving the bandwidth as a negative number.
The filter width should be at least one octave like 2-4 and 8-16. The number of octaves can be given with number of
frequencies so then there is no need to calcule the correct bands.
It is recommended to use a 1-2 octave filter and when using the option
of specifying octaves, the geometric center frequency is always used.
At ther end of the calculations, the octaves and filter bands is
written out.
Default stations: The stations and components that will be used if not specified in the codaq.inp file.
The stations are on the first line and the components on the second line. A
maximum of 300 channels can be used.
THE 2 LINES MUST BE THERE CONTAIN AT LEAST SOME BLANK CHARACTERS, if not, stations will not be read from codaq.inp file and the program will crash.
.
Since the user probably wants to calculate coda Q at the given frequency, the normal
option (new in SEISAN7.2) is that
and
are calculated such that the
given bandwidth (e.g. 4 Hz) is used, but the actual
and
will
give the specified central frequency. It is still possible to calculate
as before, where
and
will be exactly as specified (but the
geometrical center frequency will not correspond to specified center
frequency) by giving the bandwidth as a negative number.
The filter width should be at least one octave like 2-4 and 8-16. The number of octaves can be given with number of
frequencies so then there is no need to calcule the correct bands.
It is recommended to use a 1-2 octave filter and when using the option
of specifying octaves, the geometric center frequency is always used.
At ther end of the calculations, the octaves and filter bands is
written out.
Default stations: The stations and components that will be used if not specified in the codaq.inp file.
The stations are on the first line and the components on the second line. A
maximum of 300 channels can be used.
THE 2 LINES MUST BE THERE CONTAIN AT LEAST SOME BLANK CHARACTERS, if not, stations will not be read from codaq.inp file and the program will crash.
Use of components; Component blank: Note that the program will use the first available component for the given station in waveform file. The compoent actually selected will be shown in output and on plot. Component with orientation e.g. Z: First Z-channel for station is se|lelected.
After reading the parameter file, the program will by default use the codaq.inp file to get the event station information. However, any other name can be used if specified interactively, see below. The station codes can have up to 5 characters.
The codaq.inp file will consist of a series of lines each giving an event identifier (an INDEX file). An easy way to generate the file is using the SELECT program. The file can also be generated with EEV using the (C)opy option making a file called indexeev.out. An example, where default stations are used, is shown below:
1 /top/seismo/seismo/REA/BER__/1992/06/16-0343-38L.S199206
3 /top/seismo/seismo/REA/BER__/1992/06/16-1311-58L.S199206
7 /top/seismo/seismo/REA/BER__/1992/06/30-1504-30L.S199206
Since the above example only uses the default stations given in codaq.par there are no stations in the input file. Below is an example where particular stations and components have been selected with particular events, for this to work the station line and component line in codaq.par MUST be blank. Component lines can be blank or only with orientation.
1 /top/seismo/seismo/REA/BER__/1992/06/16-0343-38L.S199206
HYA KMY BER ASK TRO
S Z S E B E S Z S Z
3 /top/seismo/seismo/REA/BER__/1992/06/16-1311-58L.S199206
HYA
Z
7 /top/seismo/seismo/REA/BER__/1992/06/30-1504-30L.S199206
HYA EGD
S E Z
Note that the numbers to the left originate from the index file and do not have any importance. The long name with the directory structure, is the name of the pick file (S-file) in the database, if the S-file is in the local directory, it can have just the event id, in this example starting with 30-....The waveform file name is in the S-file. Following the S-file name is, (like in the parameter file), first a line with station codes followed by a line of component codes. Like in the parameter file, if a component is not given, the first compoent with given station name will be chosen. THE COMPONENT LINE MUST BE THERE, EVEN IF BLANK. Since it can be quite a lot of work to generate this file manually with both stations and components, SELECT has an option to generate it, see SELECT. SELECT is able to make an output file with all event-station combination within a given range. However, SELECT will give incomplete component names since not complete in S-file. It is possible to use one or three components. The file from SELECT is called index.codaq.
Below is an example of a codaq.inp file, where it is assumed that the S-files are the current directory. This file can also be generated with DIRF.
16-0343-38L.S199206
HYA KMY BER ASK TRO
16-1311-58L.S199206
HYA
S E
30-1504-30L.S199206
HYA EGD
S N S E
In the above examples, all results from one run are averaged. However it can sometimes be desirable to run several datasets and get individual results from each. There is therefore the option of running one set of events with many different sets of stations and for each set, the reults are written out separately. Typically in a large area, one would want to get codaq for each station or small groups of stations using a large earthquake set. This can be done using several sets of default stations, see example below.
SUE KMY S Z S Z ASK S Z ODD1 S Z SUE S ZIn this example, the first dataset has two stations, the others only one. The summary output for each dataset is given in file codaq.summary . An example is seen below, for abbreviations, see later:
SUE S Z KMY S Z ntotal= 37 q0= 71 sd= 25 v= 1.19 sd= 0.14 cor= 0.99 ASK S Z ntotal= 10 q0= 54 sd= 22 v= 1.19 sd= 0.19 cor= 0.98 ODD1 S Z ntotal= 11 q0= 61 sd= 19 v= 1.25 sd= 0.13 cor= 0.99 SUE S Z ntotal= 20 q0= 54 sd= 26 v= 1.27 sd= 0.19 cor= 0.98
Average coda Q is also calculated for each station or channel. The default is to calculate average for all components for each station. The output is given in file codaq.channel and also with more details in codaq1.out. Optionally the averages can be made for each channel if codaq is called with the argument -c. An example of an output file with channel averages is seen below.
PIL BH Z n= 4 q10= 1066 q0=147 sd= 5 v= 0.86 sd= 0.01 cor= 1.00 PIL BH N n= 5 q10= 1012 q0= 87 sd= 25 v= 1.06 sd= 0.12 cor= 0.99 PIL BH E n= 5 q10= 995 q0= 66 sd= 9 v= 1.18 sd= 0.08 cor= 1.00 YJI BH Z n= 11 q10= 1033 q0=113 sd= 5 v= 0.96 sd= 0.03 cor= 1.00 YJI BH N n= 3 q10= 965 q0=107 sd= 33 v= 0.96 sd= 0.13 cor= 0.99
Q10 is Q at 10 Hz.
Peter Voss : Tue Jun 8 13:38:42 UTC 2021