Next: 12. Extracting events from Up: 11. Searching in the Previous: 11.1.4 Select with input Contents Index
Written by Bladimir Moreno, August, 2014, bladimir@cenais.cu
This is a program to search in a SEISAN Nordic file (S-file) for the calculated stress drop, make average stress drop and Mw for each event using all channels or selected channels as well as average for the whole data set of several events. Only channels with a stress drop of 1 bar or more is used and the upper limit of stress drop to use in average is user selectable. The output is the average stressdrop for each event versus magnitude Mw, average stressdrop for the whole data set and a statistics of the stress drop distribution. In addition events can be selected in a lat-lon polygon.
NOTE: Only works with Nordic format spec lines.
In SEISAN stress drops are calculated with either MULPLT in a manual or semiautomatic way, automatically with AUTOSIG and automatically with AUTOMAG (a simplified AUTOSIG) either directly or through EEV command av. In each S-file, the average stress drop (as well as the average of other source parameters) is calculated when the event is updated, irrespective of the value of the stressdrop. The stressdrop is a good indicator of the quality of the spectral fitting and stress drops less 1 and higher than 200 bars usually indicate an unreliable spectrum. The program GETSTRESSDROP will therefore be useful for making reliable average stress drops using only the best data and channels.
The user calls the program with command line arguments. The first argument is obligatory and the rest are optional. The program is called in the following way:
getstressdrop <nordic.inp> [ -c <stress_cut> ] [ -s <stationslist_file.inp> ] [ -p <points_polygon.inp> ]
Nordic.inp: an S-file, any name.
stress_cut: the maximum stress drop to consider in the searching process.
stations.lis: a file (any name) with the station-channels list, with the same format as written in the line SPEC of the S-FILES format, see example later.
points_polygon.inp: a file (any name) with longitude, latitude pairs. The last point of the polygon must be equal to the first (close polygon), see example below.
20.0 -76.7 20.0 -75.0 19.5 -75 19.5 -76.7 20.0 -76.7
Output getstressdrop_histo.out: number of stressdrops in steps of 10 bars, can be plotted with LSQ.
getstressdrop_mw.out: list of earthquake magnitudes Mw versus stressdrop, can be plotted with LSQ.
Example run
getstressdrop eev.out 1996 6 6 0648 23.8 L 63.005 3.955 8.0 TES 5 2.9 2.8LTES 2.7WTES 3.0LNAO1 SPEC FOO S Z MO 13.5 ST 26.2 OM 1.5 f0 12.7 R0.1754 AL 0.00 WI 10.0 MW 2.9 3 SPECHASK S Z MO 12.9 ST 7.7 OM 0.7 f0 13.0 R0.1713 AL 0.00 WI 10.0 MW 2.6 3 SPEC EGD S Z MO 12.9 ST 24.1 OM 0.6 f0 20.0 R0.1114 AL 0.00 WI 10.0 MW 2.5 3 SPEC ASK S Z MO 13.0 ST113.0 OM 1.7 f0 17.5 R0.0738 AL 0.00 WI 20.0 MW 2.6 3 SPEC EGD S Z MO 13.1 ST 35.7 OM 1.8 f0 10.9 R0.1185 AL 0.00 WI 20.0 MW 2.7 3 SPEC BLS5S Z MO 13.2 ST 5.8 OM 1.8 f0 5.66 R0.2281 AL 0.00 WI 20.0 MW 2.7 3 1996 6 7 1325 29.2 L 59.846 5.130 12.0F TES 12 0.6 1.9LTES 2.2CTES 2.0LNAO1 SPEC EGD S Z MO 12.0 ST 12.8 OM 1.1 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 1.9 3 SPEC KMY S Z MO 12.2 ST 23.5 OM 1.2 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.1 3 SPECHASK S Z MO 12.2 ST 23.5 OM 1.2 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.1 3 SPEC ODD1S Z MO 12.3 ST 27.8 OM 1.2 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.2 3 SPEC BLS5S Z MO 12.2 ST 23.1 OM 1.1 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.1 3 SPEC SUE S Z MO 12.4 ST 32.8 OM 1.1 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.2 3 SPEC HYA S Z MO 12.3 ST 29.3 OM 1.0 f0 20.0 R0.0690 AL 0.00 WI 20.0 MW 2.2 3 SPEC FOO S Z MO 12.5 ST 23.9 OM 1.1 f0 16.4 R0.0842 AL 0.00 WI 20.0 MW 2.3 3 Average stress drop for 2 earthquakes selected: 30.0 Total number of channels used: 14 File with stress drop histogram is getstressdrop_hist.out File with stress drop as a function of magnitude mw is getstressdrop_mw.out
Each selected channel is printed out and in the end there is information of the total number of events and channels used.
An example of a channel selection file stat is:
HASK1S Z HYA S Z
It could also be written
HASK1S Z HYA S Z
Note that station names with 5 characters on SPEC line uses the 5. character on the line for the first character in station name.
Stress drop versus magnitude can give an indication if stress drops
are reliable. According to the theory of self similarity (see e.g.
Havskov and Ottemöller [2010]), stress drops should be magnitude independent.
For small earthquakes (
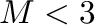 ) it might be difficult to get a reliable
corner frequency, it will often be to small due to near surface
attenuation (kappa, see MULPLT section). This results in smaller stress
drops for smaller events than larger events. It is therefore useful
to plot the stress drop versus magnitude. Figure
11.1
shows an example made with program LSQ.
) it might be difficult to get a reliable
corner frequency, it will often be to small due to near surface
attenuation (kappa, see MULPLT section). This results in smaller stress
drops for smaller events than larger events. It is therefore useful
to plot the stress drop versus magnitude. Figure
11.1
shows an example made with program LSQ.
It is seen that there is only a slight tendency to increasing stress drop with magnitude indicating reliable stress drops.
The distribution of stress drops can also be plotted with LSQ. Figure 11.2 shows an example of the data from 11.1.
![\begin{figure}\centerline{\includegraphics[width=0.9\linewidth]{fig/stressdrop}}\end{figure}](img116.png)
![\begin{figure}\centerline{\includegraphics[width=0.9\linewidth]{fig/stressdrophistogram}}\end{figure}](img117.png)